The art of structuring real-time data streams into actionable insights
Speaker
About this talk
For updates and more, join our community 👉 https://www.linkedin.com/company/devoxx-united-kingdom Real-time data can be messy, unpredictable, and hard to manage. To unlock its full potential, you need a way to turn raw streams into clean, structured data. In this talk, we’ll show you how to use Apache Kafka, Apache Flink, and Apache Iceberg to organize real-time data streams efficiently and prepare them for advanced use cases, including AI applications. We’ll start by explaining how Kafka handles high-speed data streams and how Flink processes these streams in real time. You’ll learn how to use Flink to transform raw data into structured formats, ensuring it’s ready for storage and analysis. Then, we’ll dive into Iceberg, demonstrating how it stores and organizes structured data for easy querying, versioning, and integration with machine learning pipelines. Through clear examples, we’ll walk you through building a practical pipeline that turns chaotic data streams into organized schemas. By the end of the session, you’ll know how to manage real-time data effectively and set the stage for downstream AI and analytics. Whether you’re a beginner or an experienced developer, this talk will give you the tools to simplify and enhance your data pipelines!
More talks to watch
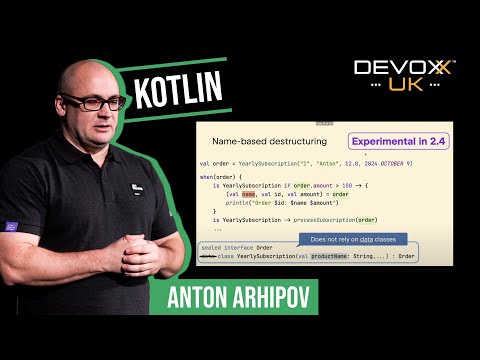 Kotlin - the new and noteworthyAnton Arhipov
Kotlin - the new and noteworthyAnton Arhipov Dockerfiles, Jib ..., what's the best way to run your Java code in Containers?Matthias Haeussle
Dockerfiles, Jib ..., what's the best way to run your Java code in Containers?Matthias Haeussle How to survive as a developer in the exponential age of AI - KeynoteSander Hoogendoorn
How to survive as a developer in the exponential age of AI - KeynoteSander Hoogendoorn Your frontend is ☠️ ⚠️ Let's measure its impact with CO2 jsKo Turk
Your frontend is ☠️ ⚠️ Let's measure its impact with CO2 jsKo Turk Using Apache Kafka and OpenSearch to explore MastodonOlena Kutsenko
Using Apache Kafka and OpenSearch to explore MastodonOlena Kutsenko Let’s use IntelliJ as a game engine, just because we canAlexander Chatzizacharias
Let’s use IntelliJ as a game engine, just because we canAlexander Chatzizacharias